A.64. Concurrency Pattern: Simplified Fan-out Fan-in Pipeline
Pada chapter sebelumnya, yaitu chapter A.63. Concurrency Pattern: Pipeline, kita telah mempelajari tentang pipeline pattern, yang mana pattern tersebut merupakan rekomendasi dari tim Go dalam meng-handle jenis kasus serangkaian proses yang berjalan secara konkuren.
Penulis sangat anjurkan untuk mencoba mempelajari praktik chapter sebelumnya terlebih dahulu jika belum. Karena chapter kali ini ada hubungannya dengan chapter tersebut.
Pada chapter ini kita akan mempelajari concurrency pattern juga, lanjutan dari sebelumnya. Pada versi ini kalau dilihat dari perspektif coding penerapannya akan lebih ringkas. Tapi apakah lebih mudah dan lebih performant dibanding penerapan pipeline sebelumnya? Jawabannya sangat tergantung dengan kasus yang dihadapi, tergantung spesifikasi hardware-nya juga, dan mungkin juga tergantung dengan taste dari si engineer pembuat program.
Kalau dilihat lebih dalam, perbedaannya sebenarnya hanya pada bagian Fan-out Fan-in nya saja. Di metode ini (hampir) semua pipeline isinya adalah gabungan dari Fan-out dan juga Fan-in. Jadi kita tidak perlu report merge. Selain itu, di sini kita bisa dengan mudah mengatur jumlah worker sesuai kebutuhan.
Ok, agar lebih jelas mari kita mulai praktik.
A.64.1. Skenario Praktik
Kita akan modifikasi file program 1-dummy-file-generator.go yang pada chapter sebelumnya sudah dibuat (A.63. Concurrency Pattern: Pipeline). Kita rubah mekanisme generate dummy files-nya dari sekuensial ke konkuren.
A.64.2. Program Generate Dummy File Sequentially
Ok langsung saja, pertama yang perlu dipersiapkan adalah tulis dulu kode program versi sekuensialnya. Bisa langsung copy-paste, atau tulis dari awal dengan mengikut tutorial ini secara keseluruhan. Untuk penjelasan detail program versi sekuensial silakan cek saja di chapter sebelumnya saja, di sini kita tulis langsung agar bisa cepat dimulai bagian program konkuren.
Siapkan folder project baru, isinya satu buah file 1-generate-dummy-files-sequentially.go.
◉ Import Packages dan Definisi Variabel
package main
import (
"fmt"
"log"
"math/rand"
"os"
"path/filepath"
"time"
)
const totalFile = 3000
const contentLength = 5000
var tempPath = filepath.Join(os.Getenv("TEMP"), "chapter-A.64-simplified-fan-in-fan-out-pipeline")
◉ Fungsi main()
func main() {
log.Println("start")
start := time.Now()
generateFiles()
duration := time.Since(start)
log.Println("done in", duration.Seconds(), "seconds")
}
◉ Fungsi randomString()
func randomString(length int) string {
randomizer := rand.New(rand.NewSource(time.Now().Unix()))
letters := []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
b := make([]rune, length)
for i := range b {
b[i] = letters[randomizer.Intn(len(letters))]
}
return string(b)
}
Sejak Go 1.20, fungsi global
math/randsudah otomatis di-seed. Untuk penggunaan umum,rand.New(rand.NewSource(...))tidak diperlukan lagi. Cukup gunakanrand.Intn()ataurand.IntN()(Go 1.22+) secara langsung.
◉ Fungsi generateFiles()
func generateFiles() {
os.RemoveAll(tempPath)
os.MkdirAll(tempPath, 0755)
for i := 0; i < totalFile; i++ {
filename := filepath.Join(tempPath, fmt.Sprintf("file-%d.txt", i))
content := randomString(contentLength)
err := os.WriteFile(filename, []byte(content), 0644)
if err != nil {
log.Println("Error writing file", filename)
}
log.Println(i, "files created")
}
log.Printf("%d of total files created", totalFile)
}
Pada bagian fungsi generateFiles() kali ini sedikit berbeda dibanding sebelumnya. Di sini log file created tidak ditampilkan per seratus data, melainkan setiap file sukses dibuat. Ini memang akan berpengaruh ke performa, tapi diperlukan untuk perbandingan antara file-file yang di-generate secara sekuensial vs file-file yang di-generate secara konkuren.
Kita lanjut dulu saja. Berikut adalah output jika program di atas di-run.
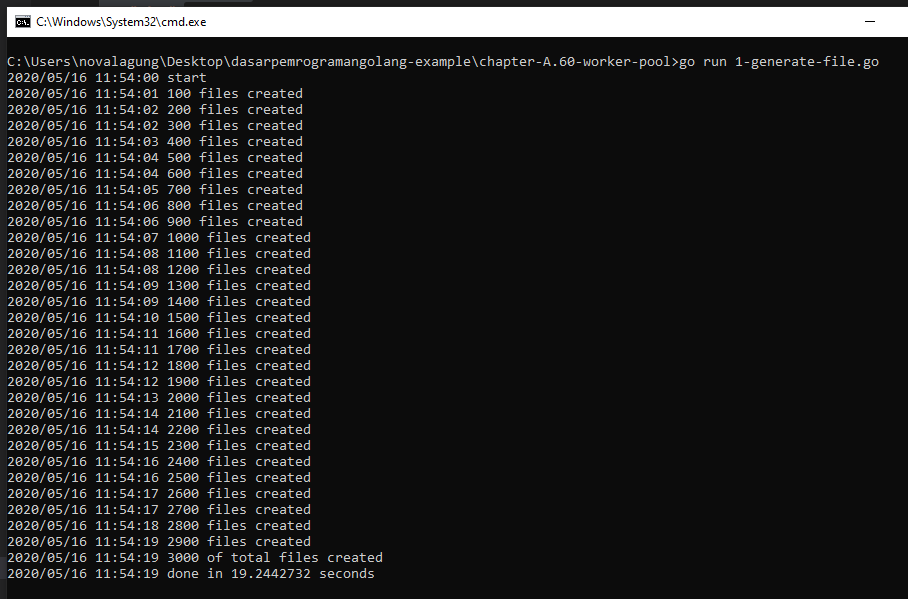
A.64.3. Program Generate Dummy File Concurrently
Selanjutnya, buat file program 2-generate-dummy-files-concurrently.go yang isinya adalah sama yaitu untuk keperluan generate dummy files tapi dilakukan secara konkuren.
◉ Import Packages dan Definisi Variabel
Import beberapa hal pada file baru ini, lalu definisikan beberapa variabel juga.
package main
import (
"fmt"
"log"
"math/rand"
"os"
"path/filepath"
"sync"
"time"
)
const totalFile = 3000
const contentLength = 5000
var tempPath = filepath.Join(os.Getenv("TEMP"), "chapter-A.64-simplified-fan-in-fan-out-pipeline")
◉ Definisi struct FileInfo
Kita perlu siapkan struct baru bernama FileInfo, struct ini digunakan sebagai skema payload data ketika dikirimkan via channel dari goroutine jobs ke goroutine worker.
type FileInfo struct {
Index int
FileName string
WorkerIndex int
Err error
}
- Property
IndexdanFileNamemenurut saya cukup jelas, isinya adalah angka dan nama file. Nama file sendiri formatnya adalahfile-<index>.txt. - Property
WorkerIndexdigunakan sebagai penanda worker mana yang akan melakukan operasi pembuatan file tersebut. - Property
Errdefault isinya kosong. Nantinya akan diisi dengan objek error ketika ada error saat pembuatan file.
◉ Fungsi main()
func main() {
log.Println("start")
start := time.Now()
generateFiles()
duration := time.Since(start)
log.Println("done in", duration.Seconds(), "seconds")
}
◉ Fungsi randomString()
func randomString(length int) string {
randomizer := rand.New(rand.NewSource(time.Now().Unix()))
letters := []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
b := make([]rune, length)
for i := range b {
b[i] = letters[randomizer.Intn(len(letters))]
}
return string(b)
}
◉ Fungsi generateFiles()
func generateFiles() {
os.RemoveAll(tempPath)
os.MkdirAll(tempPath, 0755)
// pipeline 1: job distribution
chanFileIndex := generateFileIndexes()
// pipeline 2: the main logic (creating files)
createFilesWorker := 100
chanFileResult := createFiles(chanFileIndex, createFilesWorker)
// track and print output
counterTotal := 0
counterSuccess := 0
for fileResult := range chanFileResult {
if fileResult.Err != nil {
log.Printf("error creating file %s. stack trace: %s", fileResult.FileName, fileResult.Err)
} else {
counterSuccess++
}
counterTotal++
}
log.Printf("%d/%d of total files created", counterSuccess, counterTotal)
}
Secara garis besar, isi fungsi generate files ini ada 3:
- Pipeline 1, bertugas men-dispatch goroutine untuk distribusi jobs.
- Pipeline 2, bertugas men-dispatch goroutine untuk start worker yang masing-masing worker punya tugas utama yaitu membuat files.
- Terakhir, tracking channel dari Fan-in nilai balik fungsi pipeline ke-2.
Fungsi generateFileIndexes() nantinya akan mengembalikan channel chanFileIndex yang fungsi dari channel ini adalah untuk media komunikasi antara proses dalam fungsi generateFileIndexes() (yaitu distribusi jobs) dengan proses dalam fungsi selanjutnya yaitu createFiles().
Fungsi createFiles() di sini merupakan fungsi Fan-out Fan-in karena menerima parameter channel pipeline sebelumnya, kemudian men-dispatch goroutine worker dan melacak output dari masing-masing worker ke channel output. Bisa dibilang fungsi createFiles() merupakan gabungan dari fungsi Fan-out dan Fan-in (proses merge channel output dari Fan-out juga ada di dalam fungsi tersebut).
Fungsi createFiles() menghasilkan channel yang isinya merupakan result dari operasi tiap-tiap jobs. Dari data yang dilewatkan via channel tersebut akan ketahuan misal ada error atau tidak saat pembuatan files. Channel tersebut kemudian di-loop lalu ditampilkan tiap-tiap result-nya.
◉ Fungsi generateFileIndexes()
Fungsi ini merupakan fungsi Fan-out distribusi jobs. Di dalamnya dilakukan perulangan sejumlah totalFile, kemudian data tiap index digunakan untuk pembentukan filename lalu dikirim ke channel outputnya.
func generateFileIndexes() <-chan FileInfo {
chanOut := make(chan FileInfo)
go func() {
for i := 0; i < totalFile; i++ {
chanOut <- FileInfo{
Index: i,
FileName: fmt.Sprintf("file-%d.txt", i),
}
}
close(chanOut)
}()
return chanOut
}
Setelah dipastikan semua job terkirim, kita close channel output chanOut tersebut.
◉ Fungsi createFiles()
Bagian ini merupakan yang paling butuh effort untuk dipahami. Jadi fungsi createFiles() seperti yang sudah saja jelaskan secara singkat di atas, fungsi ini merupakan fungsi gabungan Fan-out (menerima channel output dari pipeline sebelumnya) dan juga Fan-in (menjalankan beberapa worker untuk memproses channel output dari pipeline sebelumnya, lalu output masing-masing worker yang juga merupakan channel - langsung di merge jadi satu channel saja).
Mungkin lebih enak silakan tulis dulu fungsinya, kemudian kita bahas satu per satu.
func createFiles(chanIn <-chan FileInfo, numberOfWorkers int) <-chan FileInfo {
chanOut := make(chan FileInfo)
// wait group to control the workers
wg := new(sync.WaitGroup)
// allocate N of workers
wg.Add(numberOfWorkers)
go func() {
// dispatch N workers
for workerIndex := 0; workerIndex < numberOfWorkers; workerIndex++ {
go func(workerIndex int) {
// listen to `chanIn` channel for incoming jobs
for job := range chanIn {
// do the jobs
filePath := filepath.Join(tempPath, job.FileName)
content := randomString(contentLength)
err := os.WriteFile(filePath, []byte(content), 0644)
log.Println("worker", workerIndex, "working on", job.FileName, "file generation")
// construct the job's result, and send it to `chanOut`
chanOut <- FileInfo{
FileName: job.FileName,
WorkerIndex: workerIndex,
Err: err,
}
}
// if `chanIn` is closed, and the remaining jobs are finished,
// only then we mark the worker as complete.
wg.Done()
}(workerIndex)
}
}()
// wait until `chanIn` closed and then all workers are done,
// because right after that - we need to close the `chanOut` channel.
go func() {
wg.Wait()
close(chanOut)
}()
return chanOut
}
Penjelasan:
- Pertama-tama, kita siapkan
chanOutyang merupakan channel output Fan-in dari worker-worker yang ada. Channel ini langsung dijadikan nilai balik fungsicreateFiles(). Saya gunakan kata langsung di situ karena semua proses lainnya selain deklarasi channel dan waitgroup - adalah berjalan secara asynchronous via goroutine. - Kemudian objek
sync.WaitGroupdidefinisikan, lalu di-notify bahwa akan ada sejumlahnumberOfWorkersworkers berjalan secara konkuren dan harus ditunggu. Jadi waitgroup ini untuk keperluan manajemen worker-nya. - Jalankan goroutine yang isinya dispatch sejumlah
numberOfWorkersworkers. Karena pada bagian ini ada goroutine dalam perulangan, maka informasi perulangan yang akan digunakan di dalam goroutine harus dijadikan argumen eksekusi goroutine (dalam contoh iniworkerIndex). - Pantau channel
chanIn, setiap ada job yg masuk maka kerjakan. - Output dari eksekusi job ada dua yaitu: error, atau tidak error. Informasi truthy ini disimpan dalam objek
FileInforesult yang kemudian di-kirim kechanOut. - Jika perulangan terhadap
chanInsudah selesai (ditandai dengan channel-nya closed), maka kita tandai juga worker sebagai complete via statementwg.Done() - Dispatch goroutine baru lagi untuk menunggu semua worker selesai. Jika iya, maka kita close channel
chanOut.
Semoga cukup jelas ya. Kelebihan metode ini salah satunya adalah kita bisa dengan mudah menentukan jumlah workernya.
Untuk pembaca yang bingung, mungkin fungsi ini bisa dipecah menjadi satu fungsi Fan-out dan satu fungsi Fan-in seperti chapter sebelumnya.
A.64.4. Test Eksekusi Program
Saya akan coba jalankan program pertama dan kedua, lalu mari kita lihat perbedaannya.
◉ Program Generate Dummy File Sequentially
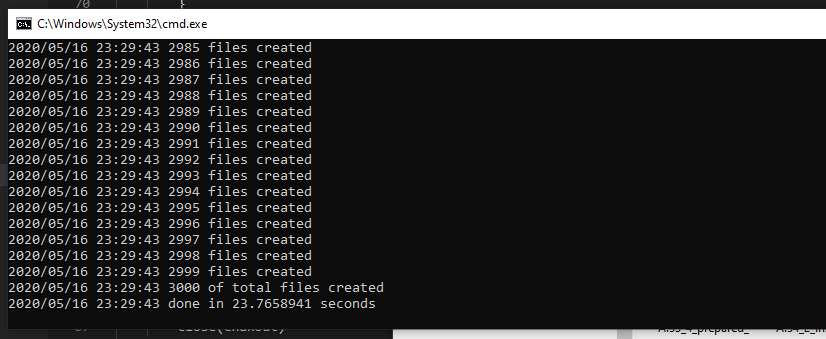
Testing di awal chapter ini hasilnya butuh sekitar 19 detik untuk menyelesaikan generate dummy files sebanyak 3000 secara sekuensial. Tapi kali ini lebih lambat, yaitu 23 detik dan ini wajar, karena di tiap operasi kita munculkan log ke stdout (via log.Println()).
◉ Program Generate Dummy File Concurrently
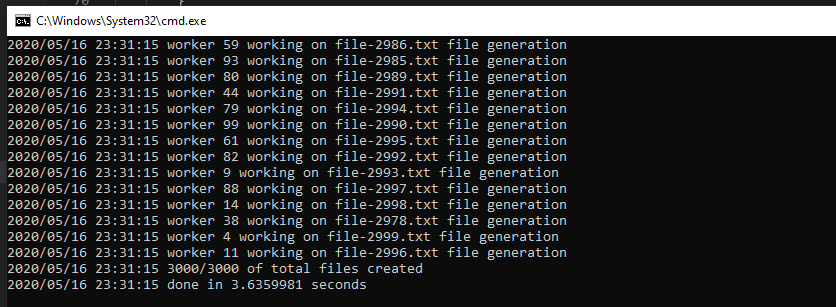
Bandingkan dengan ini, 3 detik saja! luar biasa sekali bukan beda performanya. Dan pastinya akan lebih cepat lagi kalau kita hapus statement untuk logging ke stdout (log.Println()).
Nah dari sini semoga cukup jelas ya bedanya kalau dari sisi performa. Inilah pentingnya kenapa konkurensi di Go harus diterapkan (untuk kasus yang memang bisa di-konkurensikan prosesnya). Tapi pembaca juga harus hati-hati dalam mendesain pipeline dan menentukan jumlah workernya, karena jika tidak tepat bisa makan resources seperti CPU dan RAM cukup tinggi, efeknya bisa terjadi bottleneck yang mempengaruhi performa program secara menyeluruh.
Untuk menentukan jumlah worker yang ideal, perlu banya coba-coba dan perlu dipertimbangkan juga faktor spesifikasi server/laptopnya. Jadi tidak ada angka yang pasti berapa jumlah worker ideal karena ada banyak faktor yang mempengaruhi (jenis proses, jumlah pipeline, jumlah worker per pipeline, spesifikasi hardware, dsb).